

Gli strumenti di apprendimento automatico basati sui dati genomici sono promettenti per attività di sorveglianza in tempo reale che eseguono l'attribuzione della fonte di batteri di origine alimentare come Listeria monocytogenes.
Data l’eterogeneità delle pratiche di machine learning, il nostro obiettivo era identificare coloro che influenzano le prestazioni di previsione della fonte del consueto metodo di controllo combinato con il metodo di validazione incrociata ripetuta k-fold (repeated k-fold cross-validation method).

È stata creata un'ampia raccolta di 1.100 genomi di L. monocytogenes con fonti note secondo diverse metriche genomiche per garantire l'autenticità e la completezza dei profili genomici. Sulla base di questi profili genomici (ovvero alleli a 7 locus, alleli core, geni accessori, SNP core e pan kmer), abbiamo sviluppato un flusso di lavoro versatile che valuta le prestazioni di previsione di diverse combinazioni di suddivisione del set di dati di addestramento (ovvero 50, 60, 70, 80 e 90%), preelaborazione dei dati (ovvero con o senza rimozione della varianza prossima allo zero) e modelli di apprendimento (ovvero BLR, ERT, RF, SGB, SVM e XGB). I parametri prestazionali includevano accuratezza, kappa di Cohen, punteggio F1, area sotto le curve della curva caratteristica operativa del ricevitore, curva di richiamo di precisione o curva di guadagno di richiamo di precisione e tempo di esecuzione.
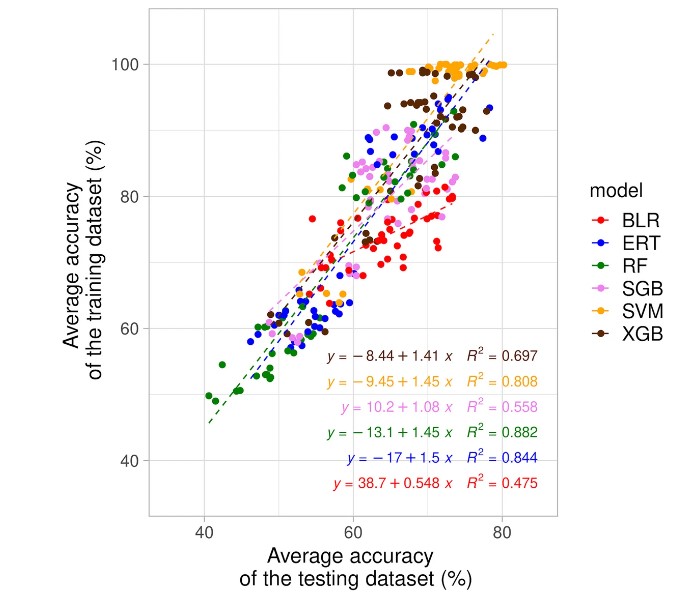
Le accuratezze medie dei test dei geni accessori e dei pan kmer erano significativamente più elevate delle accuratezze degli alleli core o degli SNP. Sebbene le accuratezze del 70 e dell'80% della suddivisione del set di dati di addestramento non fossero significativamente diverse, quelle dell'80% erano significativamente più elevate rispetto alle altre proporzioni testate. La rimozione della varianza prossima allo zero non ha consentito di produrre risultati per gli alleli a 7 loci, non ha avuto un impatto significativo sull'accuratezza per gli alleli core, i geni accessori e i pan kmer e ha ridotto significativamente l'accuratezza per gli SNP core. I modelli SVM e XGB non hanno presentato differenze significative in termini di accuratezza tra loro e hanno raggiunto, in questo ordine di grandezza, accuratezze significativamente più elevate rispetto a BLR, SGB, ERT e RF. Tuttavia, il modello SVM richiedeva una maggiore potenza di calcolo rispetto al modello XGB, soprattutto per un numero elevato di descrittori come SNP core e kmer pan.
Conclusioni
Oltre alle raccomandazioni sulle pratiche di apprendimento automatico per l'attribuzione della fonte di L. monocytogenes basata su dati genomici, il presente studio fornisce anche un flusso di lavoro disponibile gratuitamente per risolvere altri fenotipi multiclasse bilanciati o sbilanciati da profili genomici binari e categorici di altri microrganismi senza modifiche del codice sorgente...
Castelli, P., De Ruvo, A., Bucciacchio, A. et al. Harmonization of supervised machine learning practices for efficient source attribution of Listeria monocytogenes based on genomic data. BMC Genomics 24, 560 (2023). https://doi.org/10.1186/s12864-023-09667-w
